What are hash functions, and how do hashes work in crypto?


Table of Contents:
Although these terms are usually thrown around the more technical crypto circles, more than one user has wondered what hash functions are. How do hashes work to ensure secure data storage and data integrity?
The word 'hash' may evoke memories of meat and potatoes, chopped and mixed. However, food is the last thing on the menu. In this case, computers take center stage. This class of functions is all around us as long as we interact with websites, digital wallets, cryptocurrencies, digital signatures, privacy enhancing technologies, etc.
If you cannot understand these terms, this article is for you. We will explore everything about the concept of hashing, its importance in the modern digital world, existing variations, and properties of a strong hashing algorithm.
What are hash functions?
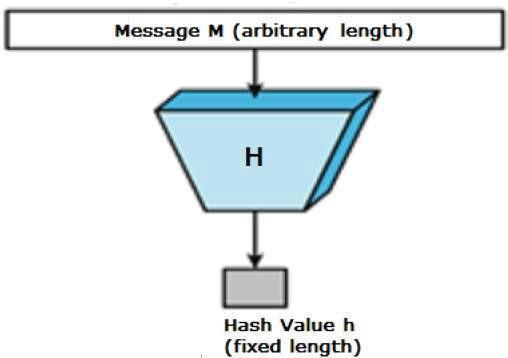
Sometimes referred to as message digest, a hash is, in short, a confusing mess. This word is used to describe the result of a person making a mess out of something and making everything worse. In computing, a hash function usually looks like letters, numbers or both jumbled up together in a way that makes no sense to the human mind. A hash function is a storage-saving tool that computers use that takes a data input, runs it through a mathematical algorithm, and converts (hashes) it into numerical values of fixed or variable lengths.
If you’ve watched enough spy movies, you must have heard of scrambled calls, which shut out unauthorized listeners by muddling up a conversation such that it becomes unintelligible. Message digest functions hash data of varying lengths and transform them into unintelligible (to humans) numeric or alphanumeric values called hash values, hash codes, or simply hashes. Unlike scrambled calls, which you can unscramble, hash functions are unidirectional, i.e., they must produce hashes that cannot be unscrambled into the original data.

After this brief overview, we must elucidate the crucial distinction between hash functions and hash values. Hash values are unique, with none having a similar makeup to another, which makes them similar to human fingerprints, as both provide authentication and data Integrity. They are usually stored in a hash table or data structure for easy access, and are of the same length if produced by the same type of hash algorithm.
Let’s use some of the most popular hashing algorithms as examples: if you scramble your 16-character Facebook password or a 56 character web link using the Secure Hash Algorithm (SHA) 256, the resulting hash values will be of the same length — a 64-character fingerprint. Even if you hashed a 10,000-word essay with SHA-256, the hash length would remain unchanged. The same would happen if you used SHA-512, with which texts of any length can be hashed yielding a fixed-size 128-character string. As the output string is encoded in hexadecimal, the 128 characters fit in exactly 512 bits.
How do hashes work?
The most critical aspect to grasp how these functions work is the mechanism by which data is scrambled to produce a fixed-length hash value or message digest. Here's a simple breakdown:
- The function takes a key as an input.
- The key is usually associated with a record and serves as a unique identifier of the record to the data storage and retrieval application.
- The key could be of a fixed length, like numbers between 10 and 20, or varying lengths, like names, or the record itself in some cases.
- The function converts the keys of fixed or varying lengths into fixed-length codes, usually of machine length. The function employs operators like ADD or XOR to fold the inputs by words or other units and preserve their parity.
- It then scrambles the key's bits to distribute the resulting values uniformly over the keyspace.
- When the hash function scrambles the record, it produces an output, a hash code, which is then used to index a hash table that holds the data or other pointers to the records.
You now know what hash functions are and how hashes work but what about their applications?
Do you know what happens in the backend when you try to log into an account with your email and password? Password verification is one of the major uses of cryptographic hash functions.
During signin up to any online platform, your password is often stored in the hash table as a hashcode. When you input your password during a login session, the function creates a checksum for the password you entered and compares it to the saved checksum of the stored password in the hash table. If both checksums are identical, access will be granted. If not, you’ll get an incorrect password message.
The applications of hash functions in cryptography are numerous. To name one of the simplest, a public key (the address you provide to someone that will send tokens or coins to you) is obtained by hashing its private key.
Hash functions in cryptography are also leveraged for file verification. If you want to download a file from an untrusted website and its checksum is provided by the original author, you can check if it matches the checksum of the original file on the trusted site.
Besides passwords and file integrity verification, Hashes also come in handy in data storage and retrieval applications and have a wide range of uses, including:
- Signature generation and verification
- Data or file identifiers
- Proof of work algorithm such as Hashcash to counter email spams and denial-of-service (DDOS) attacks.
- Hashcash is also leveraged in proof of work consensus mechanism such as Bitcoin
Types of hash functions and how they work
There are several types of hash function variations, and their distinct modes of operation set them apart. Here are a few of their most significant types in computing:
Folding
The folding method in hashing utilizes a simple two-step method to generate hash codes. First, the key value (k) is split up into a fixed number of parts, each with the same number of digits (the last part can have fewer digits). Then, the sum of all the parts will be the hash value of the input key. The number of digits in each part depends on the hash table size.
Mid-Squares
Mid-squares hashing algorithms work by squaring the input (key) and extracting a fixed number of middle digits or bits from the result of their multiplication, generating the hash. Mid-squares usually work when the data to be hashed is a numerical value, and work well when there are few leading or trailing zeros in the record's key.

Identity hash function
An identity hash function comes into play when the data hashed is small, depending on the hash code length of the programming language you intend to use. With the condition of size fulfilled, you can use the input data as a hash value, although it gets reinterpreted as an integer. This type of function can be used to map zip codes to city names.
Division hashing
As one of the easiest ways to generate a hash code, division hashing algorithms work in a simple formula that divides the value of k by M, where k is the input key and M is the hash table size (usually a prime number). Although it is fast and great for any value of M, division hashing performs poorly by mapping consecutive keys to consecutive hash codes on the hash table.
Multiplicative hashing
In multiplicative hashing, a constant value A is selected such that A is greater than zero but less than one. Then, we find the product of the input key and A, after which we extract the fractional portion X (all the digits after the decimal point). X is then multiplied by the size of the hash table, and the result is the hash code. This type of hashing is best suited to scenarios when the hash table size is the power of two.
Properties of strong hash functions algorithms

For any hashing algorithm to pass as strong, it must have the following properties:
Irreversibility
Also known as preimage resistance, irreversibility is an essential property of a strong hashing algorithm. With a good algorithm, it should be impractical to reverse the hashcode and recover the original input message. Strong hashing functions are one-way and irreversible.
Determinism
A strong hash function should always produce an output of the same size regardless of the input data size. This feature is known as determinism. Whether you are hashing the first and last names or an entire book, the hash codes produced by a specific hash function must be of the same size.
Collision resistance
Collisions in hashing occurs when two unique data inputs produce identical hashcodes. Collisions prove that a hashing function is broken and unsafe, which could invite malicious actors to manipulate data. Hash codes are unique to their data inputs, and collisions are unnatural occurrences for hashing algorithms. A robust hashing algorithm should be resistant to collision.
Avalanche effect
A strong hashing function must produce an avalanche effect when there is even the slightest change to the input key. The data blocks are handled individually: The output of the first data block is passed into the second data block as input. As a result, the output of the second block is fed into the third block, and so on. Because of this, If something as simple as a comma is added to the input, the output hashing value will change significantly.
Hash speed
A robust hashing algorithm is expected to compute hash values swiftly. Hash speed, however, is somewhat subjective, depending on how you intend to use the hashing algorithm. In some cases, like website connections, faster hashing algorithms are best suited to the job as the responsiveness contributes to a better user experience. When hashing passwords, it is best to use slower hashing functions to make sure it will much slower to brute-force the password. Thus, making it almost impossible to brute-force a large password database.
Applicability
A strong hashing algorithm must be applied in various situations and support varying input string values, hash table sizes, and seed types. For instance, one such a function that only allows specific table sizes, seed types, and limited string lengths, is less valuable than one you can use in various situations.
Uniformity
Strong hashing algorithms must ensure uniformity by mapping input values evenly across their output range. Uniformity, in this case, demands that an exact probability is used to generate each hash code in the output range. Uniformed distributions keep collisions minimal, regardless of input size, which is vital for efficient hashing.
Types of Hashing Algorithms Families
Now that you are aware of the various ways that various hashing algorithms might operate, let's examine the most well-known ones. The most popular hashing algorithms can be categorized into families. Let's take a look at three of the most common types.
- Secure Hash Algorithm (SHA): This hash family is one of the most often utilized algorithms nowadays. It consists of the SHA-1, SHA-2, and SHA-3 algorithms. SHA-2 family includes SHA-224, SHA-256, SHA-384 and sha-512 and SHA-3 includes SHA3-224, SHA3-256, SHA3-384, and SHA3-512.
- Message Digest (MD): Once popular, it’s no longer used since it’s been broken. Consists of MD2, MD4, MD5 and MD6.
- Windows NTHash: Commonly deployed in Windows systems.
Some other popular examples include BLAKE 3, RIPEMD (RACE Integrity Primitives Evaluation Message Digest) and WHIRLPOOL.
You can now confidently answer anyone asking “what are hash functions?” or “how do hashes work?”... but it doesn’t stop there.
Hashes are without a doubt a backbone of the modern Internet age. From password verifications, signature generation and data identifiers to blockchain networks, cryptographic hash functions are being used to make the digital world more secure, verifiable, and enhance users’ privacy.
As you can imagine, the hashing rabbit hole goes deep. As you increase your technical knowledge you can continue to explore every aspect of how these functions work. We hope that this superficial overview has been enlightening and achieved its primary goal of capturing your attention. If it does, please let us know through Twitter!
About Panther
Panther is a decentralized protocol that enables interoperable privacy in DeFi using zero-knowledge proofs.
Users can mint fully-collateralized, composable tokens called zAssets, which can be used to execute private, trusted DeFi transactions across multiple blockchains.
Panther helps investors protect their personal financial data and trading strategies, and provides financial institutions with a clear path to compliantly participate in DeFi.
Stay connected: Telegram | Twitter | LinkedIn | Website